Introduction
Effective release reporting is essential for the success of delivery and release management processes in today’s dynamic business landscape. However, creating valuable release reports and metrics can be a challenging task for release managers. In this post, we will explore the importance of effective release reporting and discuss how enterprise release management tools and metrics can streamline the report generation process, saving time, and improving report quality.
The Challenges of Release Reporting
Delivering a release in a complex and geographically dispersed environment is challenging, and it gets even more complicated when management asks for status updates or custom release dashboards. Reports and metrics in the release management space vary from organization to organization. Release managers often find themselves building out custom reports from various data sources such as spreadsheets, word docs, Sharepoint sites, Jira instances, PowerPoint presentations, and ITSM tools like Remedy and Service-Now. This non-centralization of data makes the acquisition, analysis, and presentation of data needed to produce release metrics a time-consuming process. As a result, release managers and coordinators may feel like their role is primarily one of release governance and reporting (MIS) function rather than one of leadership.
The Importance of Effective Release Reporting
Effective release reporting provides powerful insights into historical, in-flight, and forecasted pipeline activity and helps make decisions. Reports and metrics should be simple to read and easily accessible to stakeholders at every level from the CIO through to business and vendors who require real-time reports. To be effective, release reports should be a single source of truth that allows stakeholders to log in from any location and get the data they need when they need it. Collaboration is crucial, and the big push in the world of Agile means collaborating with colleagues who have access to the same real-time information.
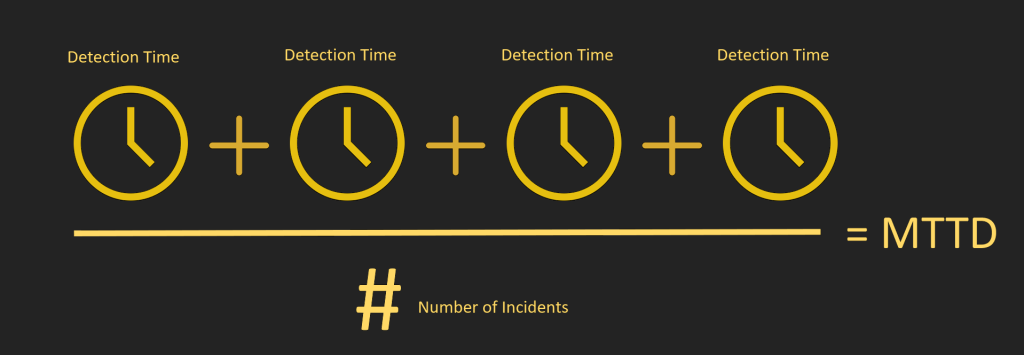
Key Metrics for Release Reporting
Here are some critical release metrics that can add value to reports:
- Cycle Time – This metric tracks the amount of time it takes for a feature or an issue to move from one stage of the release process to another.
- Defect Density – This metric measures the number of defects per unit of code.
- Deployment Frequency – This metric measures the number of releases deployed to production within a given period.
- Lead Time – This metric tracks the time it takes for a feature or an issue to move from ideation to production.
- Change Failure Rate – This metric tracks the percentage of changes that result in failure when deployed to production.
Leveraging Enterprise Release Management Tools for Effective Reporting
Enterprise release management tools can help streamline and automate the report generation process, which can save time and improve report quality. These tools ensure that reports are a single source of truth, reducing duplication of data and reports while providing real-time information. Stakeholders can log in from any location and get the data they need when they need it, making collaboration more effective.
Benefits of Streamlining Release Reporting
Using enterprise release management tools and metrics to streamline the report generation process can save time and improve report quality. It also helps release managers to focus on their leadership role, adding value to the delivery lifecycle. Moreover, the reports become easily accessible to the stakeholders, facilitating informed decision-making.
Best Practices for Creating Effective Release Reports
Release reports should be simple to read and easily accessible. Stakeholders at every level from the CIO through to business and vendors require real-time reports. Reports should be a single source of truth that allows stakeholders to log in from any location and get the data they need when they need it. It’s also essential to focus on delivering reports that add value and can be easily interpreted by non-IT folks. Finally, release managers should avoid applying too much science and report on what we call non-value numbers (metrics that don’t allow for decisions).
Conclusion
In conclusion, release reporting metrics are essential to the delivery and release management process, and release managers need to be smart about how they collect and report on releases and their required reporting metrics. If they don’t, they will find themselves having to justify their existence to the business and the value they add to the delivery lifecycle. Enterprise release management tools can help streamline and automate the report generation process, saving time and improving report quality.