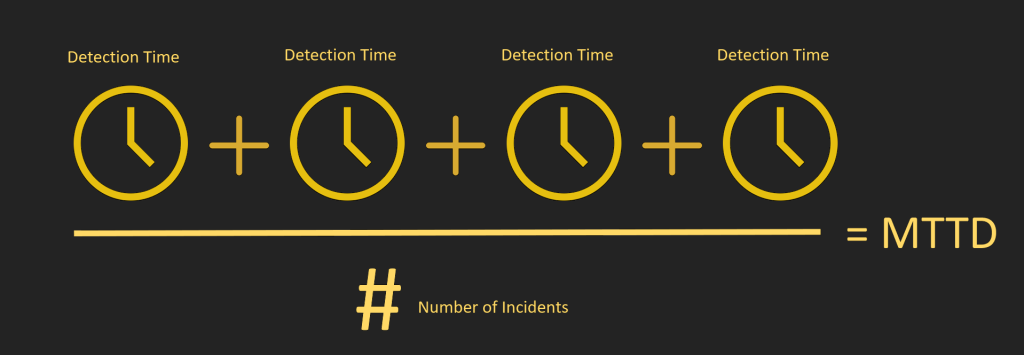
What is an OKR?
- OKR stands for Objectives and Key Results.
It is a popular goal-setting framework used by teams and individuals to set ambitious goals with measurable results. OKRs are typically set quarterly, but they can also be set annually or monthly.
How do OKRs work?
The first step in setting OKRs is to define your objectives. Objectives are qualitative statements that describe what you want to achieve. They should be ambitious but achievable.
Once you have defined your objectives, you need to identify the key results that will measure your progress towards your objectives. Key results are quantitative statements that track your progress towards your objectives. They should be specific, measurable, achievable, relevant, and time-bound.
Benefits of using OKRs
There are many benefits to using OKRs, including:
- Increased focus and alignment: OKRs help teams stay focused on the most important goals. They also help to align teams around a common vision.
- Improved transparency and accountability: OKRs are transparent and visible to everyone in the organization. This helps to improve accountability and ensure that everyone is working towards the same goals.
- Greater motivation and engagement: OKRs are motivating because they are ambitious and challenging. They also help to engage employees by giving them a sense of ownership over their work.
- Improved decision-making: OKRs provide a framework for making decisions. By understanding the organization’s goals and key results, teams can make decisions that are aligned with the organization’s priorities.
How to implement OKRs
Here are some tips for implementing OKRs:
- Start small: Don’t try to implement OKRs across the entire organization all at once. Start with a small team or department and gradually expand the program as you gain experience.
- Get buy-in from leadership: OKRs are more likely to be successful if they have the support of leadership. Make sure that your CEO and other senior leaders are on board with the program before you launch it.
- Train your team: OKRs can be a complex concept, so it’s important to train your team on how to use them effectively. Provide your team with resources and training so that they understand the framework and how to set and track OKRs.
- Be flexible: OKRs are a living document, so don’t be afraid to make changes as needed. If an objective or key result isn’t working, don’t be afraid to adjust it.
Examples of OKRs
Here are some examples of OKRs:
- Objective: Increase website traffic by 10% in the next quarter.
- Key Results:
- Increase organic search traffic by 5%.
- Increase social media traffic by 3%.
- Increase referral traffic by 2%.
- Objective: Launch a new product by the end of the year.
- Key Results:
- Complete the product design by the end of the quarter.
- Develop the product by the end of the second quarter.
- Test the product with users by the end of the third quarter.
- Launch the product by the end of the year.
OKR for TEM
Here are some specific examples of how OKRs can be used to support test environment management improvements:
- Objective: Improve the reliability of test environments.
- Key Results
- Reduce the number of outages in test environments by 50%.
- Increase the uptime of test environments to 99%.
- Objective: Improve the efficiency of test environment provisioning.
- Key Result
- Reduce the time it takes to provision a new test environment by 50%.
- Increase the number of test environments that can be provisioned simultaneously by 25%.
- Objective: Improve the security of test environments.
- Key Result
- Implement security controls in all test environments.
- Conduct security assessments of all test environments on a quarterly basis.
By using OKRs to focus on specific goals and track progress over time, teams can improve the effectiveness of their test environment management efforts
Conclusion
OKRs are a powerful goal-setting framework that can help teams and individuals achieve their goals. If you’re looking for a way to improve your focus, alignment, and motivation, consider implementing OKRs in your organization.